Cybersecurity - Federated Learning
Introduction
It has been a long time since all of our devices, such as cellphones, PCs, and smartwatches, joined the Internet. While we enjoy the benefits of this interconnected world, always being connected and not feeling like outcasts, there are predators out there trying to rob us of information, money, and more by attempting to penetrate our connected devices.
The idea of protecting our devices on the Internet motivated me to conduct this work. The goal is to leverage the panOulu public network to set up a cyber range, which will serve as a testbed for hosting the infrastructure required to train machine learning algorithms in a federated and distributed manner. This will help identify malicious activities in any public network.
What is Federated Learning?
Since privacy is important, we need a paradigm that will allow us to train our machine learning models locally while staying in harmony with other distributed models being trained in different locations. The solution lies in the federated learning paradigm.
Federated learning is a decentralized approach to machine learning that enables training models on distributed data sources without the need to transfer raw data to a central server. It allows multiple devices or edge nodes to collaboratively learn a shared model while keeping the data localized and private.
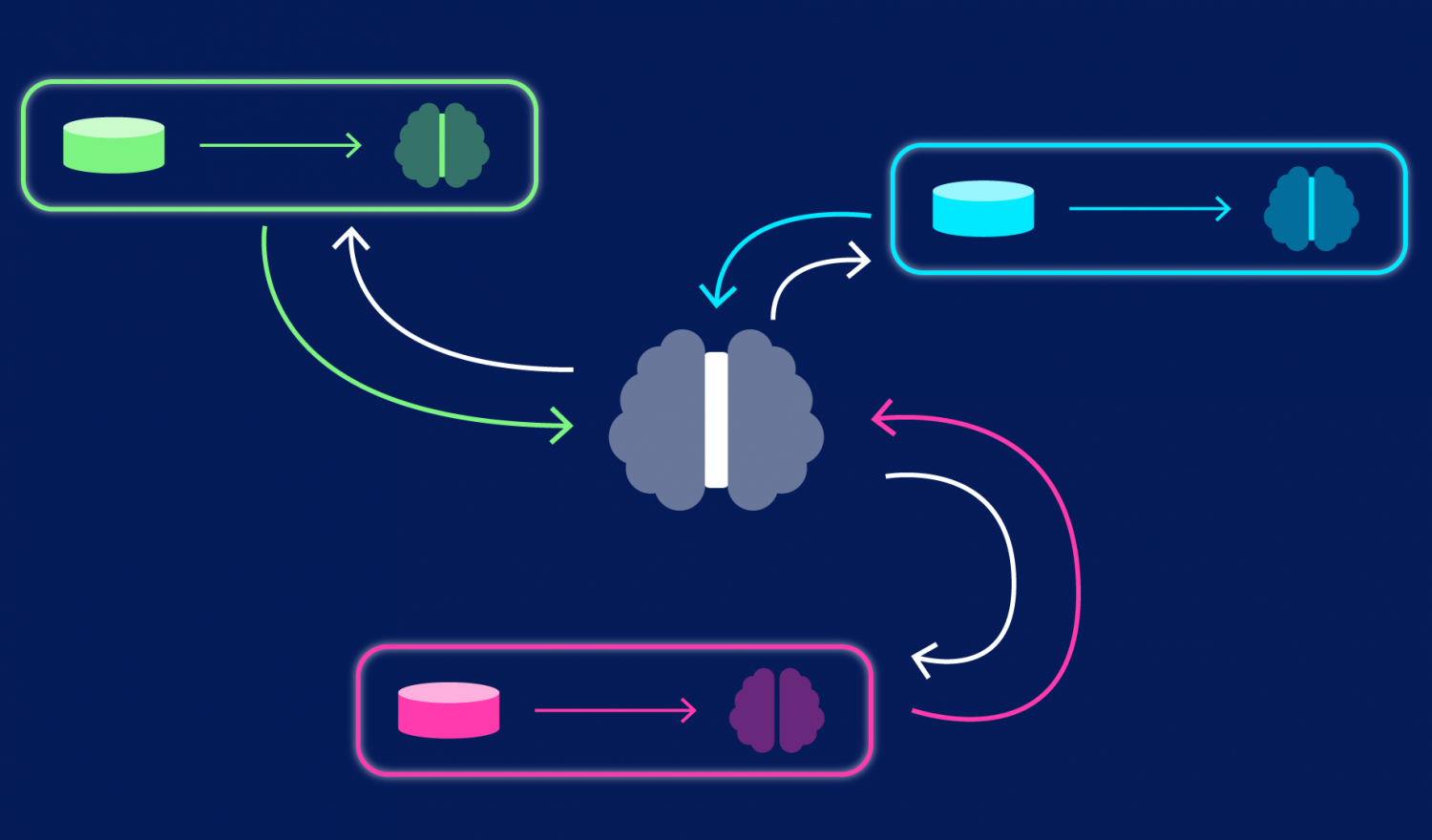
Federated learning in abstract ( picture’s ref. )
What has been set up for this project?
The following diagram shows the blueprint of the constructed testbed, which includes three tiers ranging from edge to cloud.
There are three main layers in the testbed:
- Edge layer
- Fog layer
- Cloud layer
The edge layer includes all physical devices such as IoT devices, smartphones, PCs, etc. On the other hand, the fog layer includes virtual devices hosted on physical computers using VMware vSphere technology. Finally, the cloud layer will be utilized to host the Flower server application (discussed later).
The dynamics of the testbed
Now that I have my testbed, I need to make use of it. First, I need to have access to all the network traffic from fog- and edge-layer devices to monitor and capture network activities.
To sniff packets, I deploy a distributed switch on all the fog layer’s nodes/VMs. Then, I leverage the SPAN port on the switch to receive all the traffic in the panOulu subnet. The combination of the SPAN port and the network activities that pass through the distributed switch allows me to have access to all the network packets.
Next, I plan an attack scenario on fog layer devices/nodes in the testbed and capture all the network activities to feed them to machine learning algorithms in a federated manner. The attack scenario for this work is probing, and it is limited to the fog layer devices to comply with GDPR regulations. The following figure depicts how the streaming network data is used to train federated machine learning models.
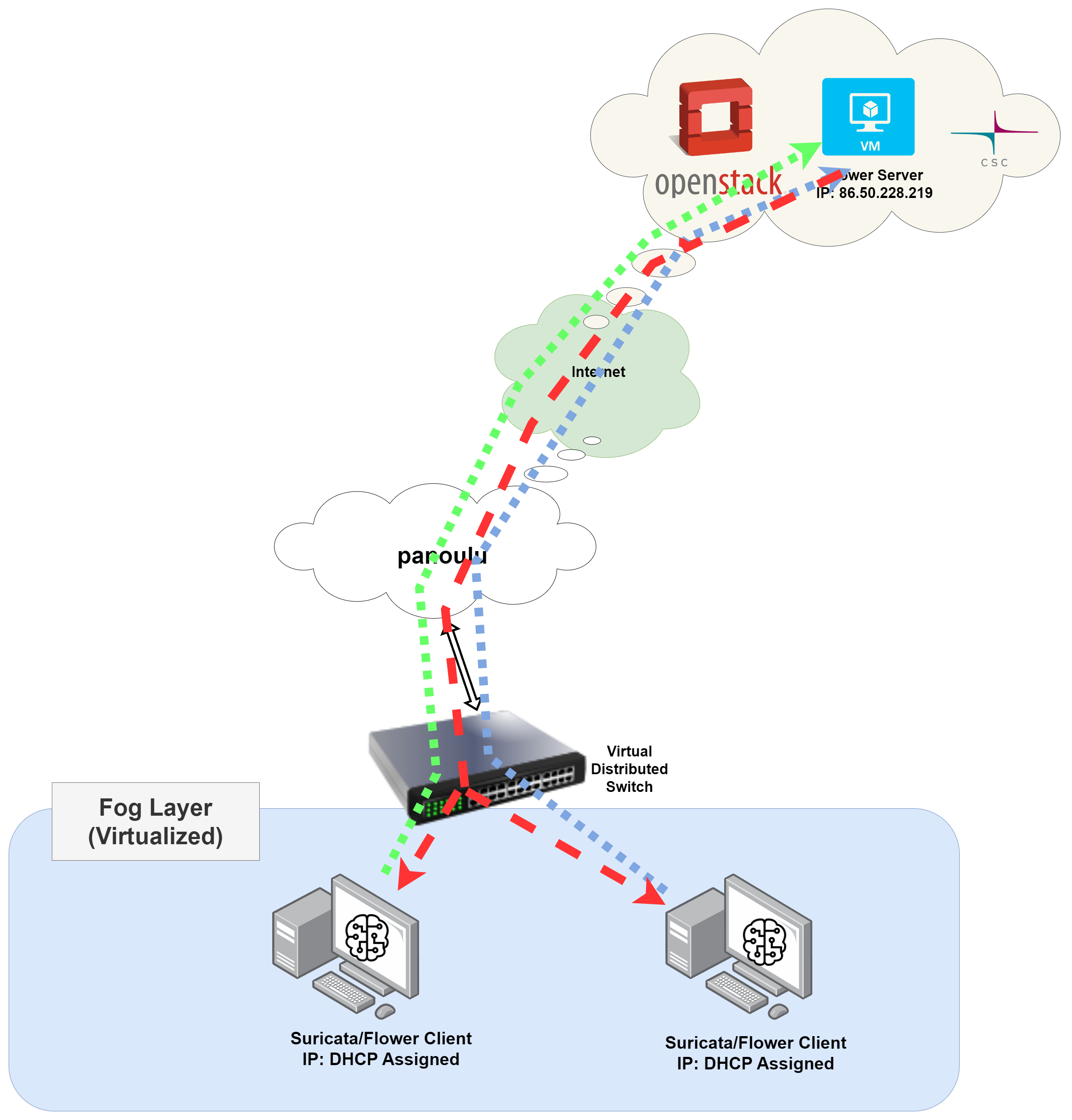
The two VMs in the diagram are installed with Suricata to capture network traffic and stream data to the local models for training. The gradients of these local models are then sent to the Flower server in the cloud to aggregate the results. The aggregated gradients are then sent back to the models to update them with each other’s results.
The benefit of the testbed
The advantage of this setup testbed is its ability to extend its usability into subnets. Since we can have subnets within each network, we can set up an environment with multiple hierarchical subnets and train machine learning models locally within each subnet. Each locally trained model can send the gradients to the Flower server for aggregation and receive back the updated gradients from the server.
This setup is especially useful when we want to create various attack scenarios that only affect certain parts of the network, rather than the entire network. For instance, a DDoS attack could be carried out on subnet A, while probing could be conducted on subnet B. In this case, the models would be able to identify both probing and DDoS attacks since they receive updated gradients from the Flower server.
Final results
During the learning phase, 485,924,228 packets were fed into the first Flower client, and 503,236,492 packets were fed into the second Flower client for training the four machine learning models. It’s important to note that the entire process, from data ingestion and storage to data processing and model training, is completely autonomous without any human interaction.
The four employed models are:
- Logistic Regression
- Stochastic Gradient Descent
- Passive Aggressive
- Perceptron
After completing the desired amount of training, which is 50 rounds in this case, the models are saved for evaluation using unseen data. For evaluation purposes, 3,000 PCAP files were captured and stored. The evaluation data can be accessed at this link. The following shows the confusion matrices for the four models on the unseen data.
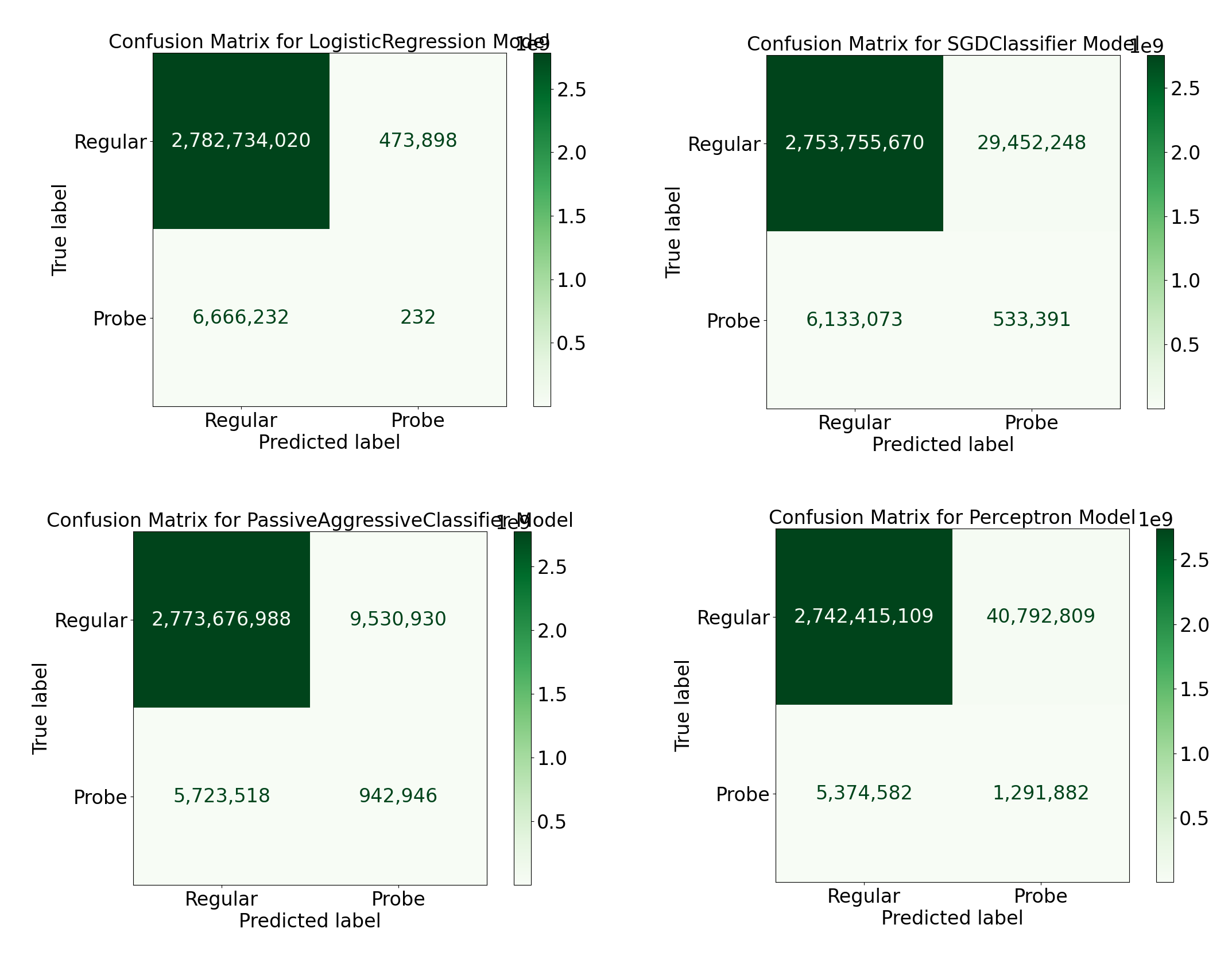
The performance of the models is influenced by the following reasons:
- Only numerical features were selected for the models, as the data had a streaming nature.
- IP address features were not utilized, in order to make the models more generalized.
- The streaming nature of the data made it challenging to normalize. Hence, no normalization was done for this work.
- Exploring the selection of additional features could have potentially yielded better results.
- The training data had an extreme imbalance, with the majority being benign packets.
- Only one tool, Tshark, was used for feature selection. Incorporating features from other tools could have influenced the results.