Twitter Brexit analysis
Introduction
Sovereignty and control, immigration concerns, economic factors, and political dissatisfactions were among the reasons that led to Brexit. Regardless of the reasons, in this project, I was interested in employing my NLP knowledge on Twitter data regarding Brexit tweets to derive inferences on people’s feelings about the British Exit. The conducted analyses include the following:
- Sentiment polarity of the tweets.
- Categorizing the tweets.
- Aversion and affection polarity of the tweets.
- Frequency of the words.
- Tagging of the named entities.
- etc.
Final result
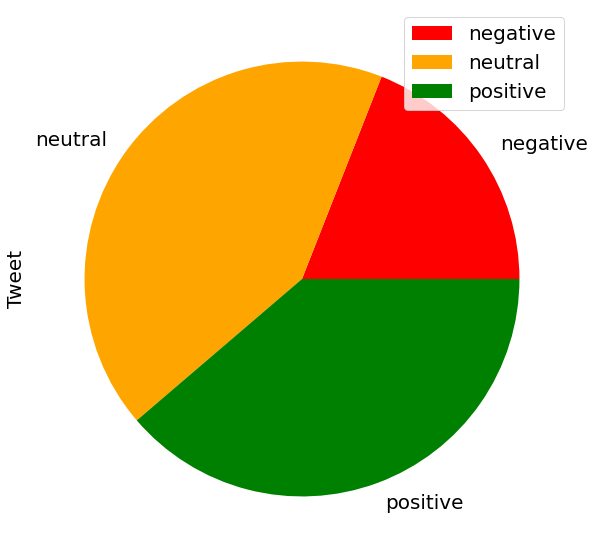
Sentiment polarity of the tweets
Based on the processed tweets, the following plots show us that almost half of the Twitter users felt neutral regarding Brexit, meaning they were neither for nor against it.
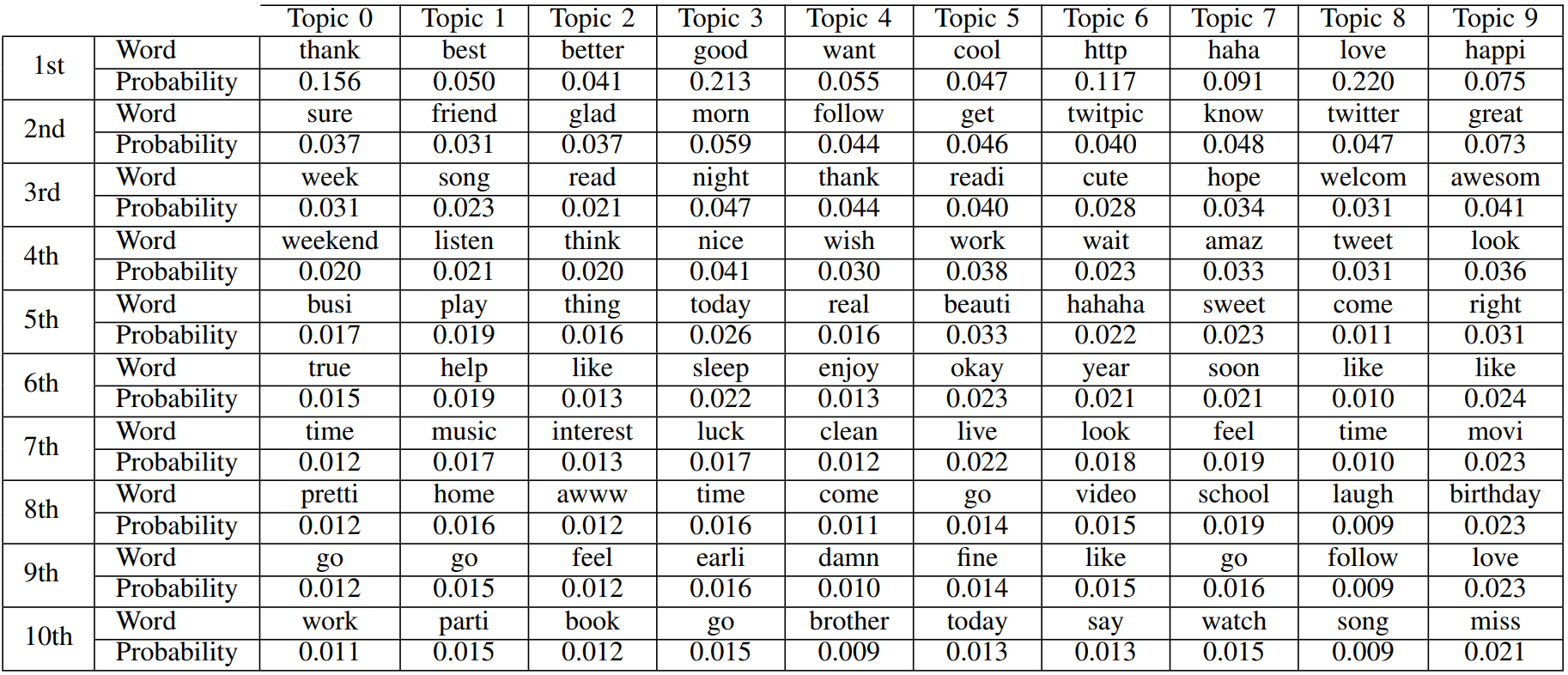
Categorizing tweets
Using Latent Dirichlet Allocation (LDA), we can categorize tweets into topics. The following shows the 10 most probable topics with the 10 most probable words in them for the positive tweets.
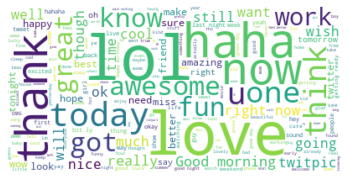
World cloud
The following show the world cloud of positive tweets.
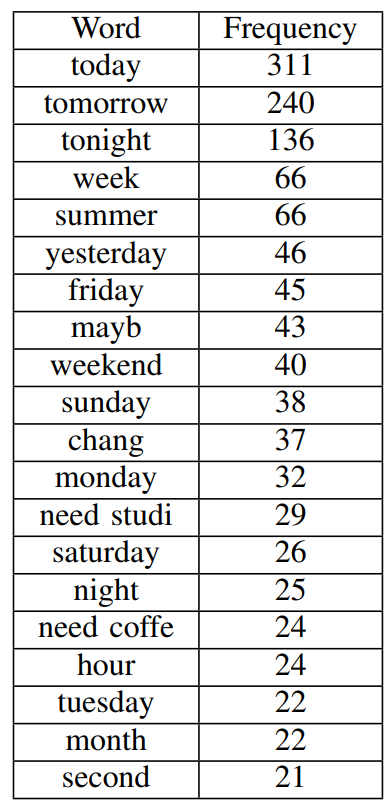
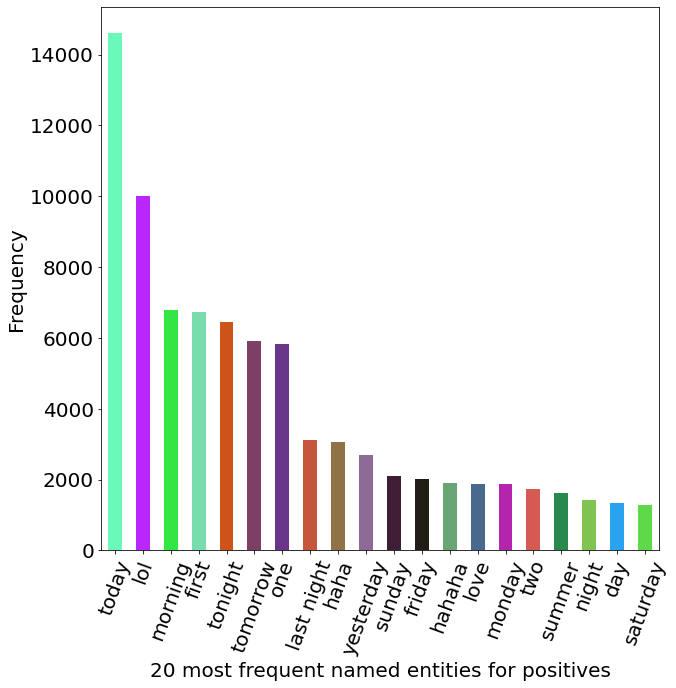
Named entities
Named entities are real-world objects such as persons, organizations, locations, dates, quantities, and other named or numeric entities that have specific names. The following shows the 20 most named entities for positive tweets.
Co-occurring words
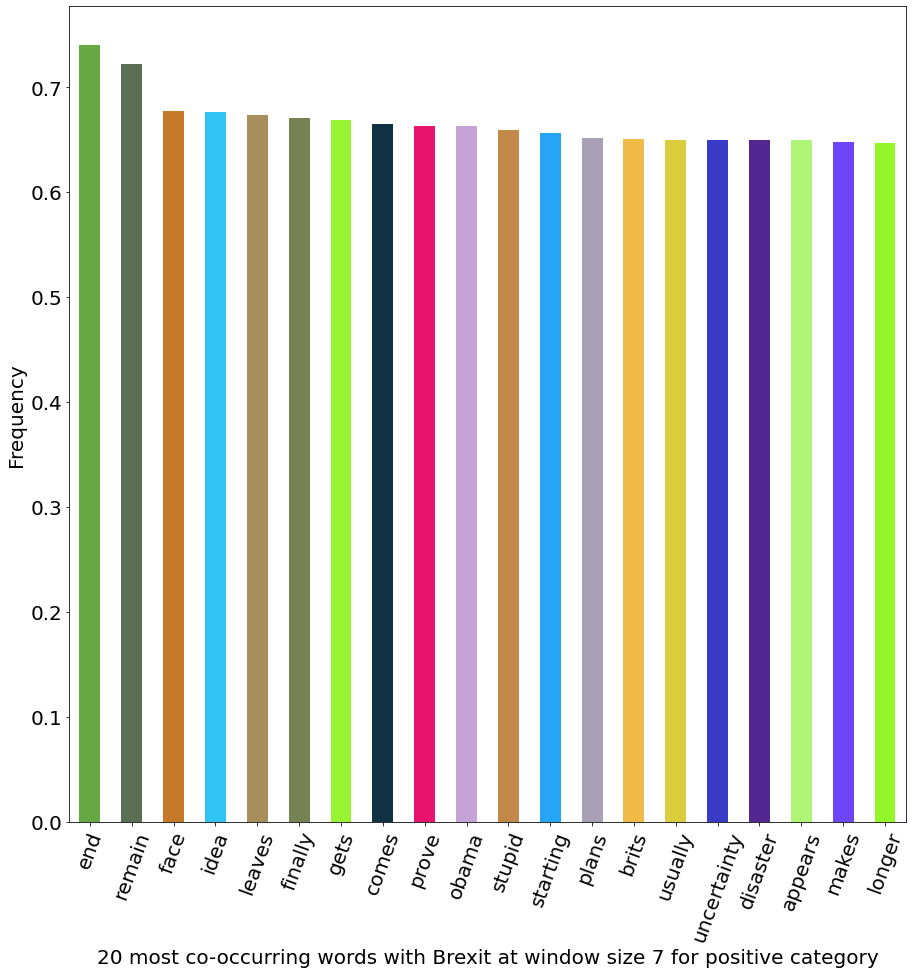
Collocations, or co-occurring words, are words that frequently appear together in a given context. The following are the most co-occurring words with “Brexit” at a window size of 7 for positive tweets.
How about the modals?
Modal auxiliary verbs, or modals, are a specific category of verbs used to express various attitudes, abilities, etc. The following are the 20 most named entities for the neutral category, containing modals such as “shall,” “must,” and “need.”